8 Statistical control
8.1 Statistical control
The nice thing about a randomized experiment is that the randomization means that there are only two possible reasons for a difference between groups in the experiment:
- researchers treating the groups differently, and
- random assignment error in which the groups were different before the researchers treated the groups differently.
Another nice thing about a randomized experiment is that a p-value under p=0.05 is sufficient in political science to consider random assignment error to not be a plausible explanation for the difference between groups. Therefore, if the p-value is p<0.05 for a difference between groups in randomized experiment, then in political science we can conclude that the difference in treatment plausibly caused the measured difference between groups.
But randomized experiments can’t be conducted for a lot of research questions. For example, we can’t randomly assign some countries to be democracies and randomly assign other countries to not be democracies. We can observe which countries are democracies and which countries are not democracies, but, on average, democracies differ from non-democracies in many ways other than the presence of democracy, such as GDP and education levels of their residents. Therefore, if we observe that democratic countries differ on average from non-democratic countries, we cannot reasonably conclude that such differences are because the countries have different levels of democracy, because the observed difference might have been caused by the difference between countries in GDP or the difference between countries in education levels of residents or the difference between countries in any other characteristic or combination of characteristics that differ between democracies and non-democracies.
However, researchers have tools that can help us make causal inferences even in the absence of the ability to conduct a randomized experiment. One such tool is called statistical control, in which researchers attempt to hold all else equal in a comparison, in order to isolate the effect of a single characteristic. The randomization of a randomized experiment can produce groups that are very similar to each other on all possible characteristics. The intent of statistical control is to make comparisons between subsets of groups that are similar to each other on all relevant characteristics, so that the comparison can isolate the effect of the factor that we are interested in.
The logic of statistical control is hold all else equal in comparisons between groups. Suppose, for instance, that a particular company paid male workers more on average than the company paid female workers on average. That gender gap could be due to the company’s unfair gender bias against female workers, but that gender gap could be due to other factors, such as if, on average, female workers chose to work fewer hours than male workers chose to work.
Let’s illustrate statistical control using the table below of hypothetical data for six workers at a company:
| Gender | Pay | Time status | Gender | Pay | Time status |
|---|---|---|---|---|---|
| Male | $50 | Full-time | Female | $50 | Full-time |
| Male | $50 | Full-time | Female | $20 | Part-time |
| Male | $20 | Part-time | Female | $20 | Part-time |
Based on the table, the mean pay is $40 among male workers and is $30 among female workers. So that’s a gender gap of $10 in mean pay per worker. Let’s first run an analysis that does not use statistical control:

Next, let’s control for full-time/part-time status, by comparing male workers to female workers at the same level of time status:

So when we compare the mean pay among male workers who work full-time to the mean pay among female workers who work full-time, there is no gap on average: both groups make $50 on average. And when we compare the mean pay among male workers who work part-time to the mean pay among female workers who work part-time, there is no gender gap: both groups make $20 on average. So – in the analysis without statistical control – the gender gap in pay favored men, but – when controlling for full-time/part-time status – there is no gender gap.
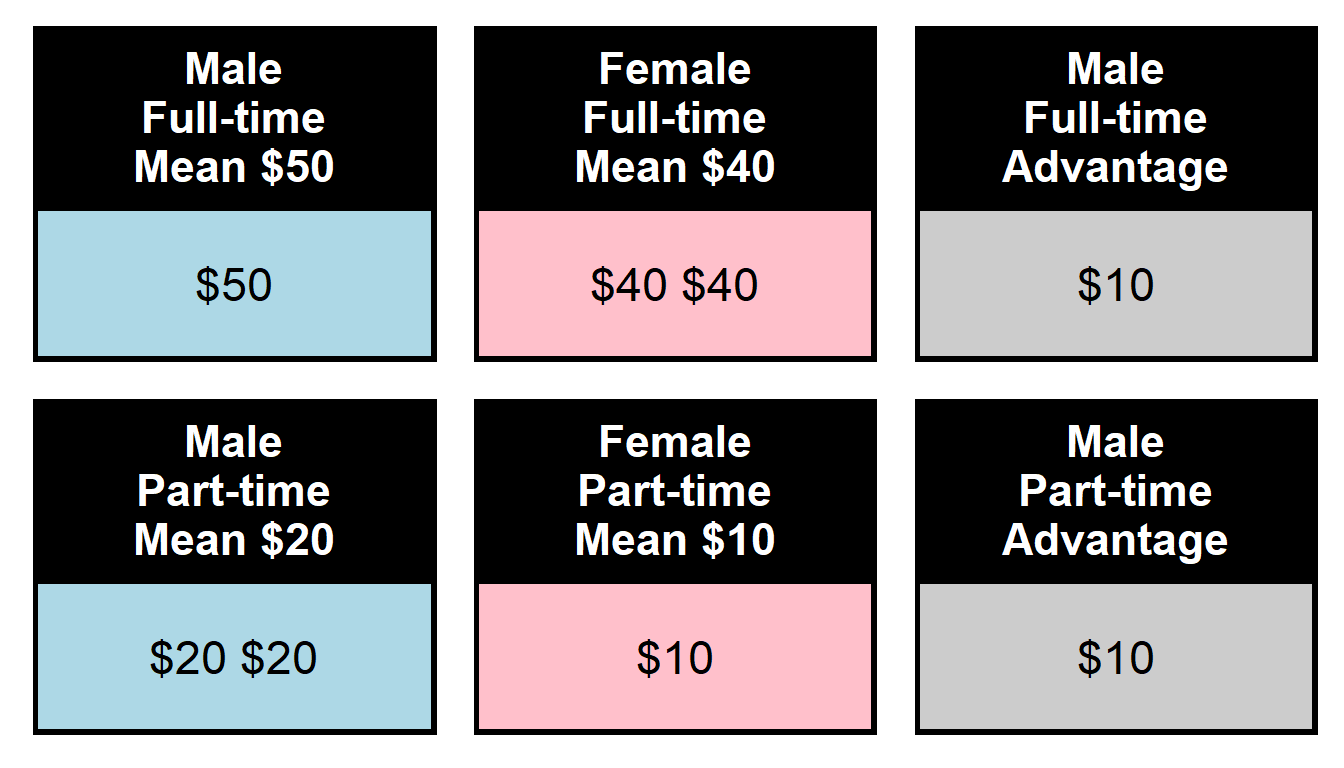
Statistical control can make an estimated difference smaller, make an estimated difference larger, or not change an estimated difference. Below is an example in which there is no gender gap in an analysis without statistical control – male workers make $30 on average, and female workers make $30 on average – but when controlling for time status – a gender gap appears, suggesting that female workers are unfairly paid less than male workers. Let’s start with the comparison without statistical control:
| Gender | Pay | Time status | Gender | Pay | Time status |
|---|---|---|---|---|---|
| Male | $50 | Full-time | Female | $40 | Full-time |
| Male | $20 | Part-time | Female | $40 | Full-time |
| Male | $20 | Part-time | Female | $10 | Part-time |

But below is the comparison with statistical control for time status:
In a world without gender bias, worker pay would probably depend on more factors than whether a worker is full-time or part-time, and, thankfully, statistical control can involve more than one control variable. The logic is the same with more than one control variable. Suppose that we wanted to control for time status (full-time or part-time) and years of relevant work experience (from, say, 0 years of relevant work experience to 40 years of relevant work experience). For that analysis, we could compare the mean pay among full-time male workers with 0 years of relevant work experience to the mean pay among full-time female workers with 0 years of relevant work experience, then compare the mean pay among part-time male workers with 0 years of relevant work experience to the mean pay among part-time female workers with 0 years of relevant work experience, then compare the mean pay among full-time male workers with 1 year of relevant work experience to the mean pay among full-time female workers with 1 year of relevant work experience, and so on. Then we could average across each of these gaps to get an estimate of the overall gender gap in mean pay controlling for time status and years of relevant work experience.
Sample practice items
Statistical control helps causal inference in non-experimental research by…
- eliminating measurement error in the outcome
- getting groups similar to each other before the groups are treated differently
- helping to address alternate explanations
- adjusting the data to be normally distributed
Answer
- helping to address alternate explanations
Suppose that you were asked to conduct a study to determine whether male ISU employees are paid more than female ISU employees are paid. For each ISU employee, you have data on the employee’s pay and their gender. Using these pay data as the outcome, would you need control variables for this study?
- Yes
- No
Answer
- No
We are interested merely in whether male ISU employees are paid more than female ISU employees are paid, so there is no need to control for anything. However, if we were interested in whether male ISU employees are unfairly paid more or less than female ISU employees are paid, then we would need to control for alternate explanations such as hours worked.
Suppose that you were asked to conduct a study to determine whether male ISU employees are unfairly paid more than female ISU employees are paid. For each ISU employee, you have data on the employee’s pay and their gender. Using these pay data as the outcome, would you need control variables for this study?
- Yes
- No
Answer
- Yes
Suppose that an analysis on data from a large representative set of college students indicated that college students who had majored in political science had a higher mean level of political knowledge at graduation than college students who had majored in earth science. The p-value for the difference in means was p<0.05. Is this sufficient evidence to conclude that, at least among the students in the study and at least on average, majoring in political science caused a higher mean level of political knowledge than majoring in earth science did?
- Yes
- No
Answer
- No
Suppose that, for a POL 138 course, all students attend the first class meeting in person and take a pretest about content that will be taught during the course. The teacher then permits each student to choose whether the student will attend the remainder of the POL 138 class meetings in Zoom or in person, before the in-person POL 138 final exam. Half of the students choose the Zoom option, and half of the students choose the in-person option. A researcher is interested in the extent to which, compared to attending POL 138 in Zoom, attending POL 138 in person affected student scores on the final exam, at least on average. For this analysis, explain the benefit of controlling for the student’s score on the POL 138 pretest.
Answer
Controlling for the student’s score on the POL 138 pretest age helps address the alternate explanation that the difference between final exam scores for the “in person” students and final exam scores for the “Zoom” students was due to smarter students being more (or less) likely to choose the “in person” option.
Suppose that we conduct a study of all drunk driving convictions in Illinois from 2000 to 2015, and we discover that, on average, men convicted of drunk driving received longer sentences than women convicted of drunk driving. Propose control variables that should be included in an analysis to assess whether gender bias among judges causes men to be convicted of drunk driving to receive longer sentences than women convicted of drunk driving.
Answer
Good controls include but are not limited to:
- property damage caused by the drivers
- injuries and deaths caused by the drivers
- driver blood alcohol content levels
- number of prior DUIs
Below are data on the pay and years of experience of four male teachers and four female teachers:
| Teacher | Gender | Pay | Years | Teacher | Gender | Pay | Years |
|---|---|---|---|---|---|---|---|
| 1 | Male | 60 | 0 | 5 | Female | 60 | 0 |
| 6 | Female | 60 | 0 | ||||
| 2 | Male | 80 | 10 | 7 | Female | 80 | 10 |
| 3 | Male | 80 | 10 | 8 | Female | 80 | 10 |
| 4 | Male | 80 | 10 |
Calculate the gender gap in mean pay, between the mean pay of the four male teachers and the mean pay of the four female teachers.
Answer
Four male teachers: (60+80+80+80)/4 = 75Four female teachers: (60+60+80+80)/4 = 70
Gender gap in mean pay is 5.
Below are data on the pay and experience of four male teachers and four female teachers:
| Teacher | Gender | Pay | Years | Teacher | Gender | Pay | Years |
|---|---|---|---|---|---|---|---|
| 1 | Male | 60 | 0 | 5 | Female | 60 | 0 |
| 6 | Female | 60 | 0 | ||||
| 2 | Male | 80 | 10 | 7 | Female | 80 | 10 |
| 3 | Male | 80 | 10 | 8 | Female | 80 | 10 |
| 4 | Male | 80 | 10 |
Compared to the gender gap in mean pay when not controlling for experience, indicate whether the gender gap in mean pay when controlling for experience would be larger, smaller, or the same size.
Answer
Smaller. The gender gap controlling foe experience should be zero, because experience completely explains pay: each teacher with high experience has a pay of 80, and each teacher with low experience has a pay of 60, so that the gender of the teacher does not seem to matter.Below are data on the pay and experience of four male teachers and four female teachers:
| Teacher | Gender | Pay | Years | Teacher | Gender | Pay | Years |
|---|---|---|---|---|---|---|---|
| 1 | Male | 60 | 0 | 5 | Female | 60 | 0 |
| 2 | Male | 80 | 0 | ||||
| 3 | Male | 80 | 0 | ||||
| 4 | Male | 80 | 10 | 6 | Female | 80 | 10 |
| 7 | Female | 80 | 10 | ||||
| 8 | Female | 80 | 10 |
Calculate the gender gap in mean pay, between the mean pay of the four male teachers and the mean pay of the four female teachers.
Answer
Four male teachers: (60+80+80+80)/4 = 75Four female teachers: (60+80+80+80)/4 = 75
Gender gap in mean pay is 0.
Below are data on the pay and experience of four male teachers and four female teachers.
| Teacher | Gender | Pay | Years | Teacher | Gender | Pay | Years |
|---|---|---|---|---|---|---|---|
| 1 | Male | 60 | 0 | 5 | Female | 60 | 0 |
| 2 | Male | 80 | 0 | ||||
| 3 | Male | 80 | 0 | ||||
| 4 | Male | 80 | 10 | 6 | Female | 80 | 10 |
| 7 | Female | 80 | 10 | ||||
| 8 | Female | 80 | 10 |
Compared to the gender gap in mean pay when not controlling for experience, explain whether the gender gap in mean pay when controlling for experience would be larger, smaller, or the same size.
Answer
Larger. The gender gap controlling for experience should NOT be zero, because experience does not completely explain pay: all teachers with high experience have a pay of 80, but – among teachers with low experience – female teachers make less (60) than men on average (60, 80, 80).The table below contains information about six police officers.
The mean gap in citizen complaints is 15 complaints, between police officers who wore a body camera (10 complaints on average) and police officers who did not wear a body camera (25 complaints on average). Based on the table data, statistical control for the age of the police officer makes the body cameras seem ___ at reducing citizen complaints about an officer, compared to an analysis of the data without any statistical control.
- less effective
- as effective
- more effective
Answer
- less effective
Let’s compare younger officers:
Younger officer + Body camera = mean number of complaints of 20
Younger officer + No body camera = mean number of complaints of 30
Let’s compare older officers:
Older officer + Body camera = mean number of complaints of 5
Older officer + No body camera = mean number of complaints of 15
The younger officer gap is 10, and the older officer gap is 10, so the overall gap when controlling for age of the officer is 10 complaints on average. The pattern for this is that older officers get fewer complaints and older officers are more likely to wear a body camera, so that imbalance makes the body cameras look more effective at reducing complaints than the body cameras really are.
8.2 Multiple linear regression
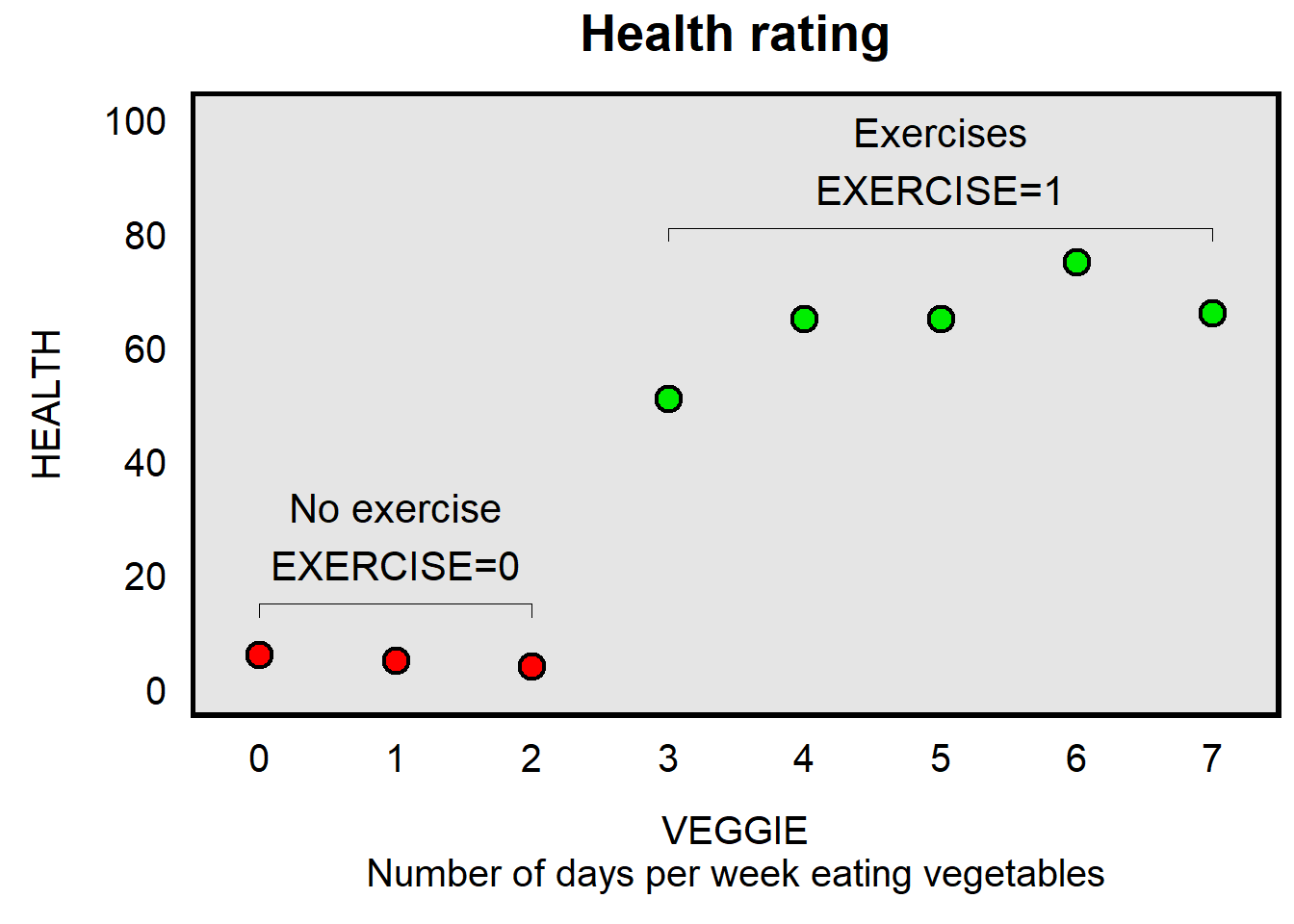
The plot below presents data for eight persons. The x-axis is VEGGIE, which indicates how many days per week that each of the eight persons eats vegetables, the y-axis is HEALTH, which indicates a rating about how healthy the person is, and the color of the dots indicates whether the person exercises, with a red dot indicating that the person does not exercise and a green dot indicating that the person exercises (with a variable called EXERCISE).
Let’s use linear regression to draw a line of best fit through these points, as shown below. The linear regression predicts the HEALTH rating using only the VEGGIE variable, so this plot colors all points black because this linear regression did not use data from the EXERCISE variable.
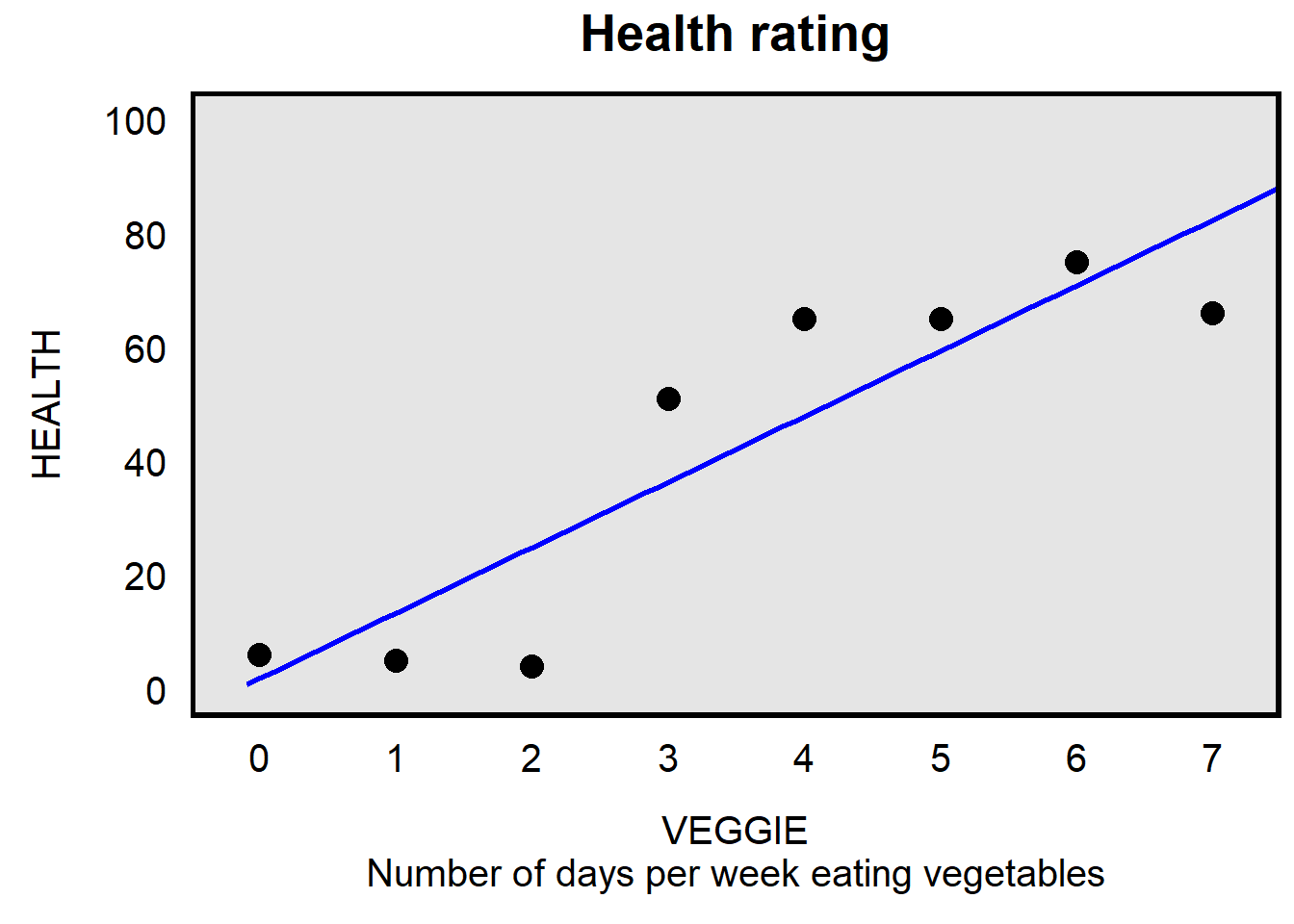
The output below is for the above linear regression. The constant/intercept coefficient of 1.83 is the y-intercept, which indicates the predicted value of the outcome HEALTH when the predictor VEGGIE is set to zero. This can be interpreted as indicating that, based on the linear regression, a person who eats vegetables zero times per week would be predicted to have a HEALTH rating of 1.83. The coefficient of 11.51 for VEGGIE indicates the slope of the linear regression line. This can be interpreted as indicating that, compared to persons who eat vegetables a particular number of days per week, a person who eats vegetables one more day per week is predicted to have a HEALTH rating that is 11.51 units higher.
reg HEALTH VEGGIE, noheader
running D:\OneDrive - IL State University\2-teaching\R for teaching\POL497\prof
> ile.do ...
------------------------------------------------------------------------------
HEALTH | Coef. Std. Err. t P>|t| [95% Conf. Interval]
-------------+----------------------------------------------------------------
VEGGIE | 11.51 2.31 4.98 0.003 5.85 17.17
_cons | 1.83 9.67 0.19 0.856 -21.83 25.50
------------------------------------------------------------------------------Let’s use the linear regression output to write an equation for the line:
Y = b + mX HEALTH = 1.83 + (11.38 * VEGGIE)
We can plug in values for VEGGIE to get a predicted HEALTH rating. For example, for a person who eats vegetables 4 times per week:
HEALTH = 1.83 + (11.51 * VEGGIE) HEALTH = 1.83 + (11.51 * 4) HEALTH = 47.87
The line of best fit therefore runs through the point (X=4, Y=47.87).
In the above linear regression, the p-value for VEGGIE is p<0.05, so we can be confident at the conventional level in political science that, in these data, the association between VEGGIE and HEALTH is not due to random chance. But that doesn’t mean that we can conclude that eating vegetables more often caused people in the data to have a higher HEALTH rating. For all we know, people who eat vegetables more frequently are different in other important ways from people who eat vegetables less frequently, and these other differences might have caused part or all of the observed association between VEGGIE and HEALTH.
Let’s conduct another linear regression, but, this time, let’s control for whether a person exercises:
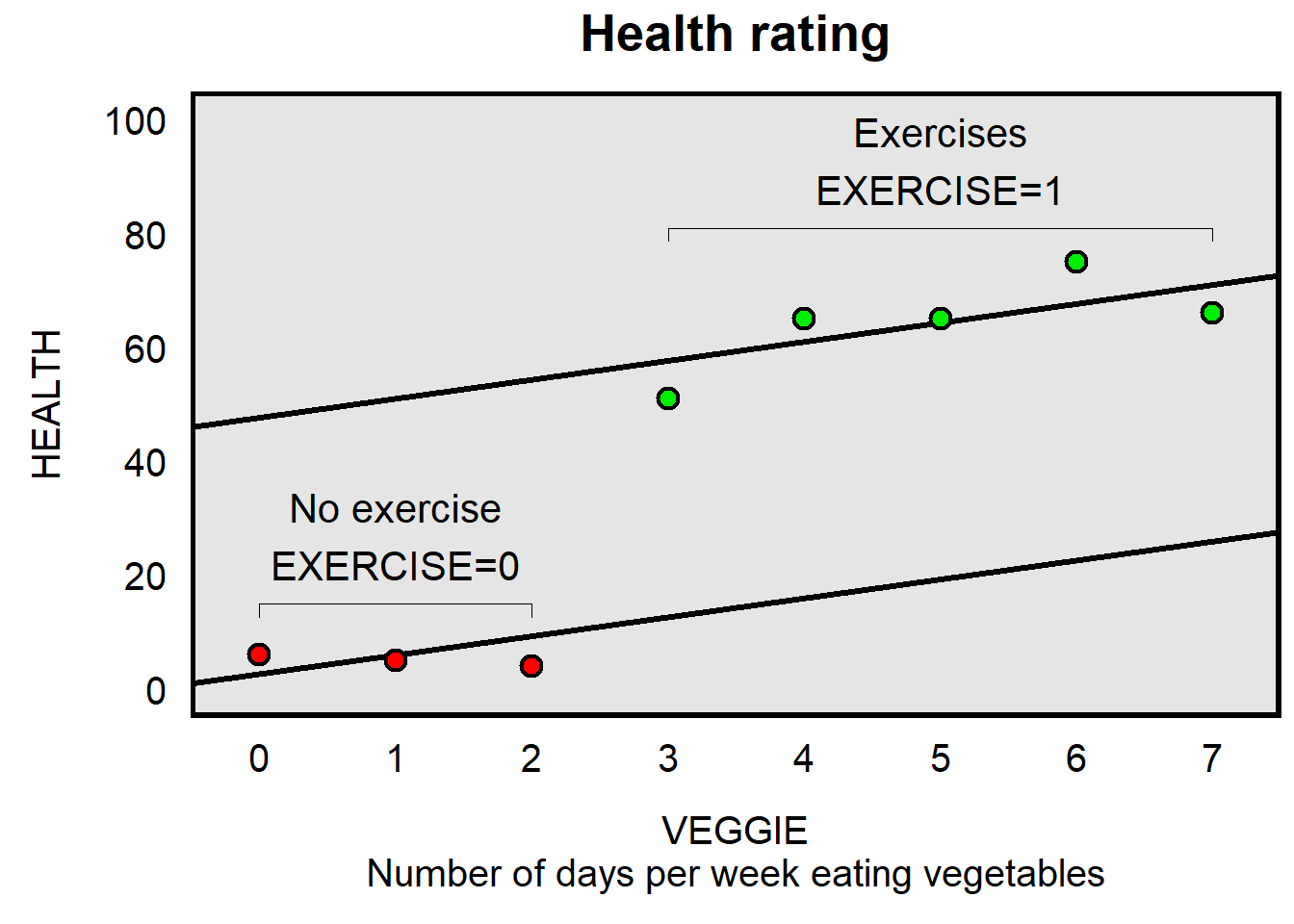
Below is the linear regression output:
reg HEALTH VEGGIE EXERCISE, noheader
running D:\OneDrive - IL State University\2-teaching\R for teaching\POL497\prof
> ile.do ...
------------------------------------------------------------------------------
HEALTH | Coef. Std. Err. t P>|t| [95% Conf. Interval]
-------------+----------------------------------------------------------------
VEGGIE | 3.17 1.72 1.84 0.124 -1.25 7.58
EXERCISE | 46.73 8.13 5.75 0.002 25.85 67.62
_cons | 1.83 3.84 0.48 0.653 -8.04 11.70
------------------------------------------------------------------------------The original coefficient on VEGGIE was 11.51. But, for the above linear regression with a control for EXERCISE, the coefficient on VEGGIE decreased to 3.17. This decrease is because much of the observed association between VEGGIE and HEALTH can be explained by the fact that people who eat vegetables more frequently also exercise, and this EXERCISE variable predicts the HEALTH rating better than the VEGGIE variable predicts the HEALTH rating.
In essence, in the regression in which the only predictor is VEGGIE, the VEGGIE coefficient is capturing the effect of VEGGIE and is capturing the effect of everything that is associated with VEGGIE, including EXERCISE. So, when EXERCISE is included in the regression as a control, the VEGGIE coefficient no longer captures the effect of EXERCISE. Of course, even with a control for EXERCISE, the VEGGIE coefficient might be capturing the effect of something else, so that we should be careful about interpreting the VEGGIE coefficient as indicating a causal effect. And, while, in this case, adding a control variable to the regression reduced the coefficient on the already-included predictor, it’s possible that adding a predictor increases the coefficient on the already-included predictor.
Let’s use this new linear regression output to write an equation for the line:
HEALTH = 1.83 + (3.17 * VEGGIE) + (46.73 * EXERCISE)
Like before, we can plug in values to get a prediction. Let’s get the predicted HEALTH rating for a person who eats vegetables 4 times per week and exercises:
HEALTH = 1.83 + (3.17 * VEGGIE) + (46.73 * EXERCISE) HEALTH = 1.83 + (3.17 * 4) + (46.73 * 1) HEALTH = 61.24
Sample practice items
The linear regression below uses survey data from the ANES 2020 Time Series Study. The output below predicts a participant’s ratings about police (FTPOLICE) using predictors for the participant’s political party (PARTY06, coded from 0 for Strong Democrat to 6 for Strong Republican) and the participant’s race (coded as White, Black, Asian, or Other race):
reg FTPOLICE PARTY06 i.RACE
running D:\OneDrive - IL State University\2-teaching\R for teaching\POL497\prof
> ile.do ...
Source | SS df MS Number of obs = 7,365
-------------+---------------------------------- F(7, 7357) = 263.61
Model | 931583.503 7 133083.358 Prob > F = 0.0000
Residual | 3714240.26 7,357 504.857993 R-squared = 0.2005
-------------+---------------------------------- Adj R-squared = 0.1998
Total | 4645823.76 7,364 630.883183 Root MSE = 22.469
------------------------------------------------------------------------------
FTPOLICE | Coef. Std. Err. t P>|t| [95% Conf. Interval]
-------------+----------------------------------------------------------------
PARTY06 | 4.11 0.12 34.08 0.000 3.88 4.35
|
RACE |
Black | -13.86 0.97 -14.23 0.000 -15.77 -11.95
Hispanic | -4.95 0.94 -5.29 0.000 -6.79 -3.12
Asian | -6.76 1.47 -4.61 0.000 -9.64 -3.89
Native | -6.87 1.84 -3.74 0.000 -10.47 -3.27
Multiracial | -9.72 1.50 -6.48 0.000 -12.66 -6.78
DK/Refused | -4.37 2.74 -1.59 0.111 -9.74 1.01
|
_cons | 61.13 0.49 124.27 0.000 60.17 62.10
------------------------------------------------------------------------------Which of the following is the better interpretation of the 2.37 coefficient for PARTY06?
- The predicted change in FTPOLICE for a one-unit increase in PARTY06.
- The predicted change in FTPOLICE for a one-unit increase in PARTY06, controlling for respondent race.
Answer
- The predicted change in FTPOLICE for a one-unit increase in PARTY06, controlling for respondent race.
In the prior regression, explain a benefit of the regression below controlling for race.
Answer
The control for respondent race addresses the alternate explanation that PARTY06 associates with FTPOLICE merely because of race. In the United States, Blacks are more likely to be Democrats than to be Republicans, so maybe the association between PARTY06 and FTPOLICE was merely because, compared to other people, Blacks are more likely to be Democrats and are more likely to rate police relatively low. The regression controlling for race indicates that the association between PARTY06 and FTPOLICE holds on average across racial groups.8.3 Illustration of the effects of statistical control
The plots below are designed to illustrate that adding statistical control can change a coefficient that is already in a regression to be less extreme than the coefficient was before or to be more extreme than the coefficient was before.
Let’s start with the “less extreme” case. For this stylized example, we have three White respondents and three non-White respondents, with measures of respondent ratings about police (FTPOLICE) and respondent age (AGE) and the measure of race called WHITE coded as 1 for White and 0 for non-White. As indicated below, a control for participant race makes the AGE coefficient less extreme: the slope of the line of best fit for AGE is 0.48 in the left plot but is only 0.20 in the right plot.
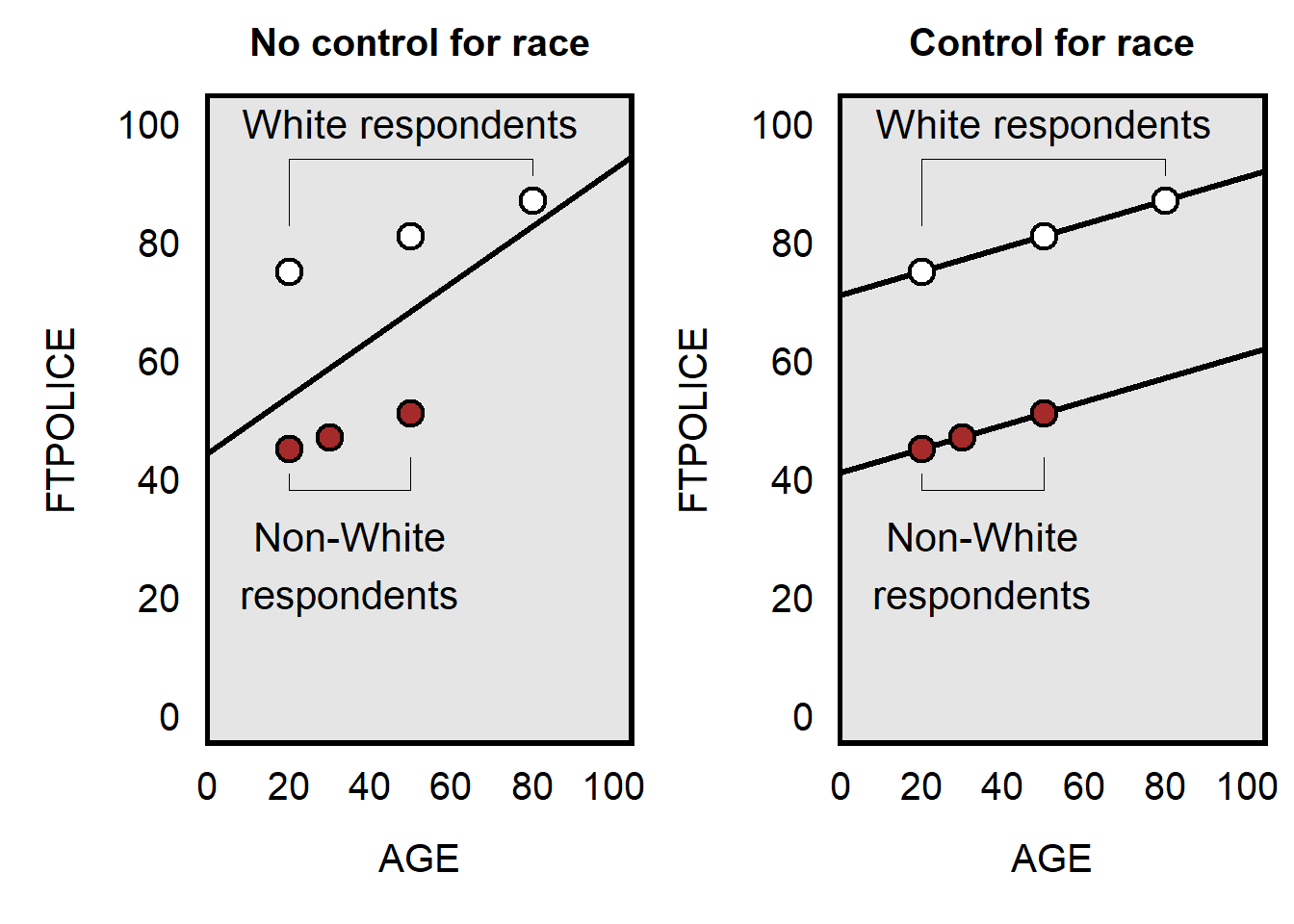
The mechanism in making the AGE coefficient less extreme is that, without a control for race, the AGE predictor is getting a boost from race: White respondents have more positive views of police, older respondents have more positive views of police, and older respondents are more likely to be White than to not be White. So the effect of age is mixed in with the effect of race. But controlling for race removes the effect of race from the coefficient for AGE.
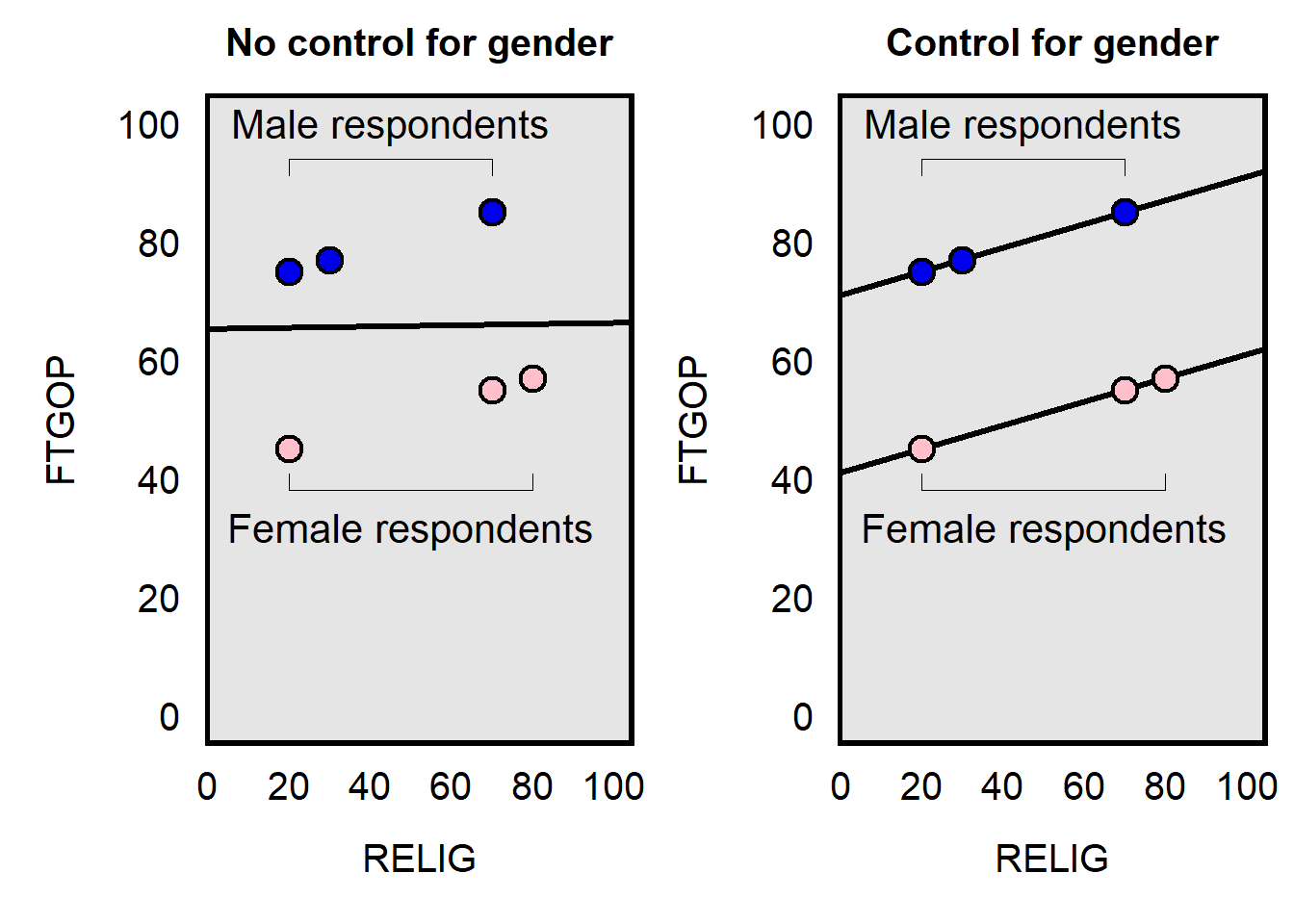
Let’s use a different stylized example to illustrate how adding statistical control can make a coefficient that is already in a regression be more extreme than the coefficient was before. For this example, we have three male respondents and three female respondents, with measures of respondent ratings about Republicans (FTGOP) and respondent religiosity (RELIG). As indicated below, a control for participant gender makes the coefficient for RELIG more extreme: the slope of the line of best fit for RELIG is 0.01 in the left plot but is 0.20 in the right plot.
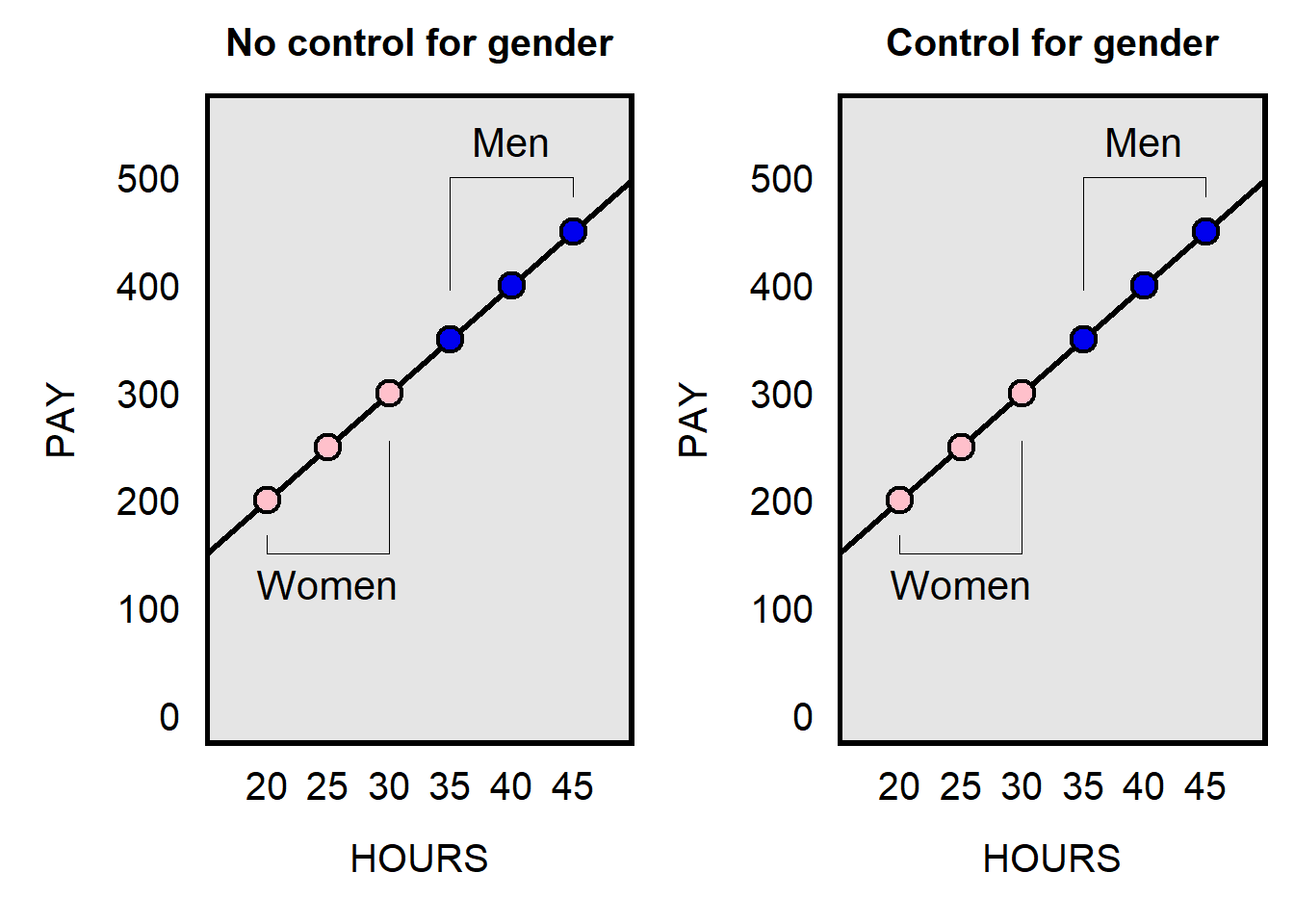
And to illustrate a situation in which statistical control does not affect the slope of a predictor already in the regression:
8.4 Multiple regression in Stata
For the ANES 2020 Time Series Study, let’s use respondent race to predict respondent’s rating about police (FTPOLICE) in a linear regression. The i. tells Stata to treat race as a categorical predictor:
svy: reg FTPOLICE i.RACE
running D:\OneDrive - IL State University\2-teaching\R for teaching\POL497\prof
> ile.do ...
(running regress on estimation sample)
Survey: Linear regression
Number of strata = 50 Number of obs = 7,388
Number of PSUs = 101 Population size = 7,382.4092
Design df = 51
F( 6, 46) = 46.27
Prob > F = 0.0000
R-squared = 0.0871
------------------------------------------------------------------------------
| Linearized
FTPOLICE | Coef. Std. Err. t P>|t| [95% Conf. Interval]
-------------+----------------------------------------------------------------
RACE |
Black | -23.3 1.6 -14.57 0.000 -26.5 -20.1
Hispanic | -10.0 1.3 -7.46 0.000 -12.7 -7.3
Asian | -11.9 1.8 -6.49 0.000 -15.6 -8.2
Native | -5.1 3.1 -1.66 0.102 -11.3 1.1
Multiracial | -13.4 3.3 -4.02 0.000 -20.1 -6.7
DK/Refused | -9.5 3.7 -2.60 0.012 -16.8 -2.2
|
_cons | 74.0 0.5 143.52 0.000 73.0 75.0
------------------------------------------------------------------------------Let’s use a tabstat command get the mean age of our racial groups, for participants in the sample:
tabstat AGE, by(RACE) stats(n mean sd min max)
running D:\OneDrive - IL State University\2-teaching\R for teaching\POL497\prof
> ile.do ...
Summary for variables: AGE
by categories of: RACE
RACE | N mean sd min max
------------+--------------------------------------------------
White | 5758 53.51181 17.10561 18 80
Black | 702 48.75214 16.08363 18 80
Hispanic | 732 43.28962 16.11707 18 80
Asian | 272 46.52941 16.30925 18 80
Native | 162 52.29012 15.12707 18 80
Multiracial | 263 44.19392 16.56921 19 80
DK/Refused | 43 55.60465 17.04635 25 80
------------+--------------------------------------------------
Total | 7932 51.58522 17.20718 18 80
---------------------------------------------------------------Results above indicate that racial groups have different mean ages, with (for example) Whites on average older than Blacks. It’s possible that, compared to younger people, older people systematically report higher or lower ratings on the feeling thermometers, so that we can’t be sure of the extent to which racial differences in ratings about police are due to age differences between racial groups. To address this, we can calculate predicted ratings by race, but control for age.
Let’s get predicted ratings about police by race, with no controls.
svy: reg FTPOLICE i.RACE AGE
running D:\OneDrive - IL State University\2-teaching\R for teaching\POL497\prof
> ile.do ...
(running regress on estimation sample)
Survey: Linear regression
Number of strata = 50 Number of obs = 7,098
Number of PSUs = 101 Population size = 7,113.0638
Design df = 51
F( 7, 45) = 93.49
Prob > F = 0.0000
R-squared = 0.1592
------------------------------------------------------------------------------
| Linearized
FTPOLICE | Coef. Std. Err. t P>|t| [95% Conf. Interval]
-------------+----------------------------------------------------------------
RACE |
Black | -22.4 1.7 -13.51 0.000 -25.8 -19.1
Hispanic | -6.4 1.4 -4.61 0.000 -9.2 -3.6
Asian | -7.9 1.6 -4.81 0.000 -11.2 -4.6
Native | -6.0 2.9 -2.10 0.041 -11.7 -0.3
Multiracial | -9.3 3.3 -2.79 0.007 -16.0 -2.6
DK/Refused | -11.7 4.7 -2.49 0.016 -21.2 -2.3
|
AGE | 0.4 0.0 14.06 0.000 0.4 0.5
_cons | 53.4 1.8 30.47 0.000 49.8 56.9
------------------------------------------------------------------------------Let’s run the regression predicting ratings about police by race, but with a control for age. The Black/White gap in mean FTPOLICE fell from 23.3 units in unadjusted analyses to 22.4 units below when controlling for age. This tells us that the Black/White gap in FTPOLICE is largely not due to the Black/White age difference.
8.5 Sending Stata regression output to a Microsoft Word file
If you want to include regression output from Stata in a paper that you write, it’s possible to output a table directly from stata, using the esttab command. This esttab command is not part of Stata but is a command that you can add on using the findit command and then installing the esttab command.
findit esttab * Let's get some data clear all set obs 200 gen X1 = runiform(0,10) gen X2 = -4*X1 + runiform(-200,200) gen Y = 3*X1 + 2*X2 + runiform(-400,400) pwcorr set cformat %9.2f * Let's get the output reg Y X1 estimates store reg1 reg Y X1 X2 estimates store reg2 esttab reg1 reg2 using regression_output.rtf, b(%99.2f) se(%99.2f) starlevels(* 0.05) r2 ar2 pr2 nogaps label onecell replace
The options above for the esttab command aren’t easy to remember, but you can put those options into an .ado file and then put the ado file into a Stata directory, so that Stata will see and run the command. Use the Stata command sysdir to see locations that Stata will draw from, and put the ado file into one of those directories. Make sure that the name that you give the program is not the name of an existing Stata command, so that Stata does not drop an existing command.
*! estwd v1.0 16 aug 2008 *! Author: L.J Zigerell Jr. *! Convenience command using esttab to output a file to Microsoft Word capture program drop estwd program define estwd esttab using regression_output.rtf, b(%99.2f) se(%99.2f) starlevels(* 0.05) r2 ar2 pr2 nogaps label onecell replace end
Feel free to change the above options to the options that you prefer.