Leftover comments from 2021
Below are leftover comments on publications that I read in 2021.
---
ONO AND ZILIS 2021
Politics, Groups, and Identities published Ono and Zilis 2021, "Do Americans perceive diverse judges as inherently biased?". Ono and Zilis 2021 indicated that "We test whether Americans perceive diverse judges as inherently biased with a list experiment". The statements to test whether Americans perceive diverse judges to be "inherently biased" were:
When a court case concerns issues like #metoo, some women judges might give biased rulings.
When a court case concerns issues like immigration, some Hispanic judges might give biased rulings.
Ono and Zilis 2021 indicated that "...by endorsing that idea, without evidence, that 'some' members of a group are inclined to behave in an undesirable way, respondents are engaging in stereotyping" (pp. 3-4).
But statements about whether *some* Hispanic judges and *some* women judges *might* be biased can't measure stereotypes or the belief that Hispanic judges or women judges are *inherently* biased. For example, a belief that *some* women *might* commit violence doesn't require the belief that women are inherently violent and doesn't even require the belief that women are on average more violent than men are.
---
Ono and Zilis 2021 claimed that "Hispanics do not believe that Hispanic judges are biased" (p. 4, emphasis in the original), but, among Hispanic respondents, the 95% confidence interval for agreement with the claim that Hispanic judges might be biased in cases involving issues like immigration did not cross zero in the multivariate analyses in Figure 1.
For Table 2 analyses without controls, the corresponding point estimate indicated that 25 percent of Hispanics agreed with the claim about Hispanic judges, but the ratio of the relevant coefficient to standard error was 0.25/0.15, which is about 1.67, depending on how the 0.25 and 0.15 were rounded. The corresponding p-value isn't less than p=0.05, but that doesn't support the conclusion that the percentage of Hispanics that agreed with the statement is zero.
---
BERRY ET AL 2021
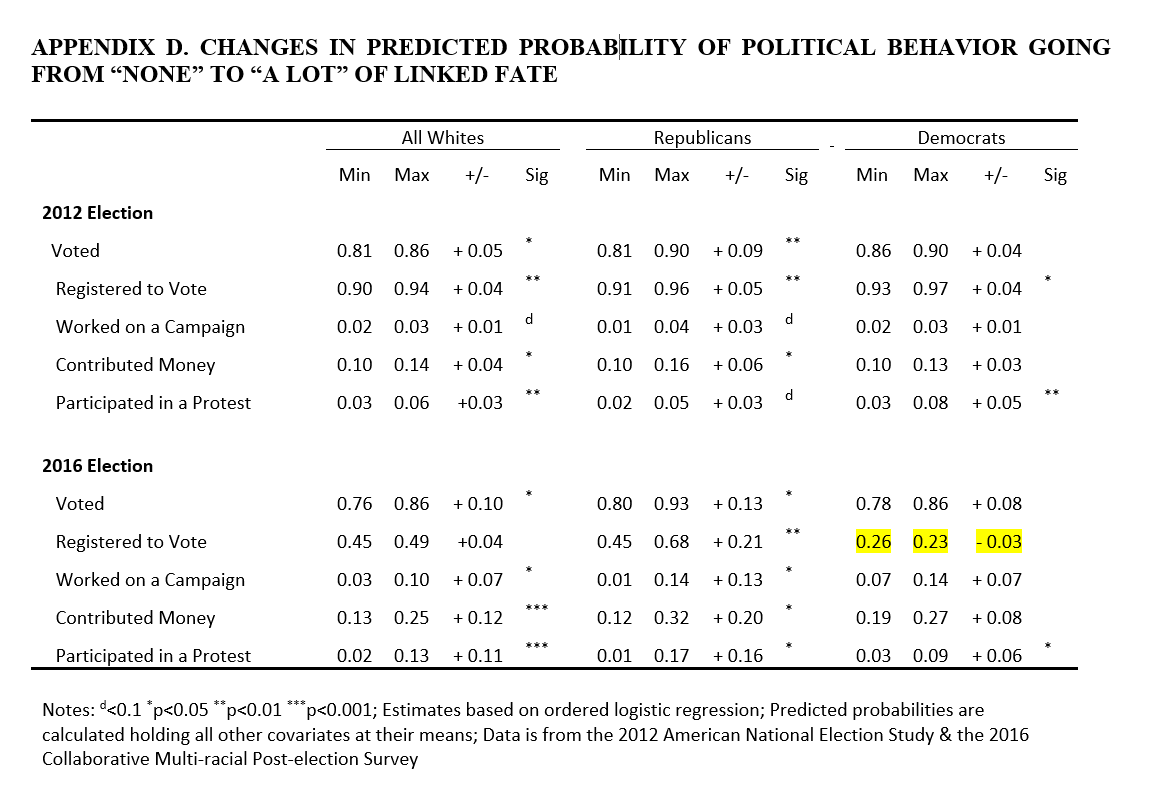
Politics, Groups, and Identities published Berry et al 2021,"White identity politics: linked fate and political participation". Berry et al 2021 claimed to have found "notable partisan differences in the relationship between racial linked fate and electoral participation for White Americans". But this claim is based on differences in the presence of statistical significance between estimates for White Republicans and estimates for White Democrats ("Linked fate is significantly and consistently associated with increased electoral participation for Republicans, but not Democrats", p. 528), instead of being based on statistical tests of whether estimates for White Republicans differ from estimates for White Democrats.
The estimates in the Berry et al 2021 appendix that I highlighted in yellow appear to be incorrect, in terms of plausibility and based on the positive estimate in the corresponding regression output.
---
ARCHER AND CLIFFORD FORTHCOMING
In "Improving the Measurement of Hostile Sexism" (reportedly forthcoming at Public Opinion Quarterly), Archer and Clifford proposed a modified version of the hostile sexism scale that is item specific. For example, instead of measuring responses about the statement "Women exaggerate problems they have at work", the corresponding item-specific item measures responses to the question of "How often do women exaggerate problems they have at work?". Thus, to get the lowest score on the hostile sexism scale, instead of merely strongly disagreeing that women exaggerate problems they have at work, respondents must report the belief that women *never* exaggerate problems they have at work.
---
Archer and Clifford indicated that responses to some of their revised items are measured on a bipolar scale. For example, respondents can indicate that women are offended "much too often", "a bit too often", "about the right amount", "not quite often enough", or "not nearly often enough". So to get the lowest hostile sexism score, respondents need to indicate that women are wrong about how often they are offended, by not being offended enough.
Scott Clifford, co-author of the Archer and Clifford article, engaged me in a discussion about the item specific scale (archived here). Scott suggested that the low end of the scale is more feminist, but dropped out of the conversation after I asked how much of an OLS coefficient for the proposed item-specific hostile sexism scale is due to hostile sexism and how much is due to feminism.
The portion of the hostile sexism measure that is sexism seems like something that should have been addressed in peer review, if the purpose of a hostile sexism scale is to estimate the effect of sexism and not to merely estimate the effect of moving from highly positive attitudes about women to highly negative attitudes about women.
---
VIDAL ET AL 2021
Social Science Quarterly published Vidal et al,"Identity and the racialized politics of violence in gun regulation policy preferences". Appendix A indicates that, for the American National Election Studies 2016 Time Series Study, responses to the feeling thermometer about Black Lives Matter ranged from 0 to 999, with a standard deviation of 89.34, even though the ANES 2016 feeling thermometer for Black Lives Matter ran from 0 to 100, with 999 reserved for respondents who indicate that they don't know what Black Lives Matter is.
---
ARORA AND STOUT 2021
Research & Politics published Arora and Stout 2021 "After the ballot box: How explicit racist appeals damage constituents views of their representation in government", which noted that:
The results provide evidence for our hypothesis that exposure to an explicitly racist comment will decrease perceptions of interest representation among Black and liberal White respondents, but not among moderate and conservative Whites.
This is, as far as I can tell, a claim that the effect among Black and liberal White respondents will differ from the effect among moderate and conservative Whites, but Arora and Stout 2021 did not report a test of whether these effects differ, although Arora and Stout 2021 did discuss statistical significance for each of the four groups.
Moreover, Arora and Stout 2021 footnote 4 indicates that:
In the supplemental appendix, we confirm that explicit racial appeals have a unique effect on interest representation and are not tied to other candidate evaluations such as vote choice.
But the estimated effect for interest representation (Table 1) was -0.06 units among liberal White respondents (with a "+" indicator for statistical significance), which is the same reported number as the estimated effect for vote choice (Table A5): -0.06 units among liberal White respondents (with a "+" indicator for statistical significance).
None of the other estimates in Table 1 or Table A5 have an indicator for statistical significance.
---
Arora and Stout 2021 repeatedly labeled as "explicitly racist" the statement that "If he invited me to a public hanging, I'd be on the front row", but it's not clear to me how that statement is explicitly racist. The Data and Methodology section indicates that "Though the comment does not explicitly mention the targeted group...". Moreover, the Conclusion of Arora and Stout 2021 indicates that...
In spite of Cindy Hyde-Smith's racist comments during the 2018 U.S. Senate election which appeared to show support for Mississippi's racist and violent history, she still prevailed in her bid for elected office.
... and "appeared to" isn't language that I would expect from an explicit statement.
---
CHRISTIANI ET AL 2021
The Journal of Race, Ethnicity, and Politics published Christiani et al 2021 "Masks and racial stereotypes in a pandemic: The case for surgical masks". The abstract indicates that:
...We find that non-black respondents perceive a black male model as more threatening and less trustworthy when he is wearing a bandana or a cloth mask than when he is not wearing his face covering—especially those respondents who score above average in racial resentment, a common measure of racial bias. When he is wearing a surgical mask, however, they do not perceive him as more threatening or less trustworthy. Further, it is not that non-black respondents find bandana and cloth masks problematic in general. In fact, the white model in our study is perceived more positively when he is wearing all types of face coverings.
Those are the within-model patterns, but it's interesting to compare ratings of the models in the control, pictured below:
 Appendix Table B.1 indicates that, on average, non-Black respondents rated the White model more threatening and more untrustworthy compared to the Black model: on a 0-to-1 scale, among non-Black respondents, the mean ratings of "threatening" were 0.159 for the Black model and 0.371 for the White model, and the mean ratings of "untrustworthy" were 0.128 for the Black model and 0.278 for the White model. These Black/White gaps were about five times the standard errors.
Appendix Table B.1 indicates that, on average, non-Black respondents rated the White model more threatening and more untrustworthy compared to the Black model: on a 0-to-1 scale, among non-Black respondents, the mean ratings of "threatening" were 0.159 for the Black model and 0.371 for the White model, and the mean ratings of "untrustworthy" were 0.128 for the Black model and 0.278 for the White model. These Black/White gaps were about five times the standard errors.
Christiani et al 2021 claimed that this baseline difference does not undermine their results:
Fortunately, the divergent evaluations of our two models without their masks on do not undermine either of the main thrusts of our analyses. First, we can still compare whether subjects perceive the black model differently depending on what type of mask he is wearing...Second, we can still assess whether people resolve the ambiguity associated with seeing a man in a mask based on the race of the wearer.
But I'm not sure that it is true, that "divergent evaluations of our two models without their masks on do not undermine either of the main thrusts of our analyses".
I tweeted a question to one of the Christiani et al 2021 co-authors that included the handles of two other co-authors, asking whether it was plausible that masks increase the perceived threat of persons who look relatively nonthreatening without a mask but decrease the perceived threat of persons who look relatively more threatening without a mask. That phenomenon would explain the racial difference in patterns described in the abstract, given that the White model in the control was perceived to be more threatening than the Black model in the control.
No co-author has yet responded to defend their claim.
---
Below are the mean ratings on the 0-to-1 "threatening" scale for models in the "no mask" control group, among non-Black respondents by high and low racial resentment, based on Tables B.2 and B.3:
Non-Black respondents with high racial resentment
0.331 mean "threatening" rating of the White model
0.376 mean "threatening" rating of the Black modelNon-Black respondents with low racial resentment
0.460 mean "threatening" rating of the White model
0.159 mean "threatening" rating of the Black model
---
VICUÑA AND PÉREZ 2021
Politics, Groups, and Identities published Vicuña and Pérez 2021, "New label, different identity? Three experiments on the uniqueness of Latinx", which claimed that:
Proponents have asserted, with sparse empirical evidence, that Latinx entails greater gender-inclusivity than Latino and Hispanic. Our results suggest this inclusivity is real, as Latinx causes individuals to become more supportive of pro-LGBTQ policies.
The three studies discussed in Vicuña and Pérez 2021 had these prompts, with the bold font in square brackets indicating the differences in treatments across the four conditions:
Using the spaces below, please write down three (3) attributes that make you [a unique person/Latinx/Latino/Hispanic]. These could be physical features, cultural practices, and/or political ideas that you hold [as a member of this group].
If the purpose is to assess whether "Latinx" differs from "Latino" and "Hispanic", I'm not sure of the value of the "a unique person" treatment.
Discussing their first study, Vicuña and Pérez 2021 reported the p-value for the effect of the "Latinx" treatment relative to the "unique person" treatment (p<.252) and reported the p-values for the effect of the "Latinx" treatment relative to the "Latino" treatment (p<.046) and the "Hispanic" treatment (p<.119). Vicuña and Pérez 2021 reported all three corresponding p-values when discussing their second study and their third study.
But, discussing their meta-analysis of the three studies, Vicuña and Pérez 2021 reported one p-value, which is presumably for the effect of the "Latinx" treatment relative to the "unique person" treatment.
I tweeted a request Dec 20 to the authors to post their data, but I haven't received a reply yet.
---
KIM AND PATTERSON JR. 2021
Political Science & Politics published Kim and Patterson Jr. 2021, "The Pandemic and Gender Inequality in Academia", which reported on tweets of tenure-track political scientists in the United States.
Kim and Patterson Jr. 2021 Figure 2 indicates that, in February 2020, the percentage of work-related tweets was about 11 percent for men and 11 percent for women, and that, shortly after Trump declared a national emergency, these percentages had dropped to about 8 percent and 7 percent respectively. Table 2 reports difference-in-difference results indicating that the pandemic-related decrease in the percentage of work-related tweets was 1.355 percentage points larger for women than for men.
That seems like a relatively small gender inequality in size and importance, and I'm not sure that this gender inequality in percentage of work-related tweets offsets the advantage of having the 31.5k follower @womenalsoknow account tweet about one's research.
---
The abstract of Kim and Patterson Jr. 2021 refers to "tweets from approximately 3,000 political scientists". Table B1 in Appendix B has sample size of 2,912, with a larger number of women than men at the rank of assistant professor, at the rank of associate professor, and at the rank of full professor. The APSA dashboard indicates that women were 37% of members of the American Political Science Association and that 79.5% of APSA members are in the United States, so I think that Table B1 suggests that a higher percentage of female political scientists might be on Twitter than male political scientists.
Oddly, though, when discussing the representatives of this sample, Kim and Patterson Jr. 2021 indicated that (p. 3):
Yet, relevant to our design, we found no evidence that female academics are less likely to use Twitter than male colleagues conditional on academic rank.
That's true about not being *less* likely, but my analysis of the data for Kim and Patterson Jr. 2021 Table 1 indicated that, controlling for academic rank, about 5 percent more female political scientists from top 50 departments were on Twitter, compared to male political scientists from top 50 departments.
Table 1 of Kim and Patterson Jr. 2021 is limited to the 1,747 tenure-track political scientists in the United States from top 50 departments. I'm not sure why Kim and Patterson Jr. 2021 didn't use the full N=2,912 sample for the Table 1 analysis.
---
My analysis indicated that the female/male gaps in the sample were as follows: 2.3 percentage points (p=0.655) among assistant professors, 4.5 percentage points (p=0.341) among associate professors, and 6.7 percentage points (p=0.066) among full professors, with an overall 5 percentage point male/female gap (p=0.048) conditional on academic rank.
---
Kim and Patterson Jr. 2021 suggest a difference in the effect by rank:
Disaggregating these results by academic rank reveals an effect most pronounced among assistants, with significant—albeit smaller—effects for associates. There is no differential effect on work-from-home at the rank of full professor, which is consistent with our hypothesis that these gaps are driven by the increased obligations placed on women who are parenting young children.
But I don't see a test for whether the coefficients differ from each other. For example, in Table 2 for work-related tweets, the "Female * Pandemic" coefficient is -1.188 for associate professors and is -0.891 for full professors, for a difference of 0.297, relative to the respective standard errors of 0.579 and 0.630.
---
Table 1 of Kim and Patterson Jr. 2021 reported a regression predicting whether a political scientist in a top 50 department was a Twitter user, and the p-values are above p=0.05 for all coefficients for "female" and for all interactions involving "female". That might be interpreted as a lack of evidence for a gender difference in Twitter use among these political scientists, but the interaction terms don't permit a clear inference about an overall gender difference.
For example, associate professor is the omitted category of rank in the regression, so the 0.045 non-statistically significant "female" coefficient indicates only that female associate professor political scientists from top 50 departments were 4.5 percentage points more likely to be a Twitter user than male associate professor political scientists from top 50 departments.
And the non-statistically significant "Female X Assistant" coefficient doesn't indicate whether female assistant professors differ from male assistant professors: instead, the non-statistically significant "Female X Assistant" coefficient indicates only that the associate/assistant difference among men in the sample does not differ at p<0.05 from the associate/assistant difference among women in the sample.
Link to the data. R code for my analysis. R output from my analysis.
---
LEFTOVER PLOT
I had the plot below for a draft post that I hadn't yet published:
Item text: "For each of the following groups, how much discrimination is there in the United States today?" [Blacks/Hispanics/Asians/Whites]. Substantive response options were: A great deal, A lot, A moderate amount, A little, and None at all.
Data source: American National Election Studies. 2021. ANES 2020 Time Series Study Preliminary Release: Combined Pre-Election and Post-Election Data [dataset and documentation]. March 24, 2021 version. www.electionstudies.org.







{kind=link}
{kind=link}
{kind=link}
{kind=link}